Top Pareto-Frontier AI Reasoning Stacks for 2025

10 cost-aware model combinations that keep students and startups on the ARC-AGI-1 frontier
Nov 20, 2025
|
12 min
TL;DR
Discover ten AI reasoning stacks ranked by ARC-AGI-1 score versus per-question cost, featuring GPT-5.1, o3-preview, Gemini 2.5, DeepSeek-R1, and Alici.ai routing strategies so you can stay on the Pareto frontier in 2025.
The ARC-AGI-1 leaderboard has turned into the cleanest economic dashboard for reasoning systems. Between late 2023 and early 2025, GPT-5.1 (Thinking-High) crept within three percentage points of o3-preview (Low) on the benchmark while slashing per-question cost from about $200 to $0.67. For university builders and lean startups, that single data point proves the Pareto frontier is sliding left (cheaper) and up (smarter) at the same time. This listicle distills ten stacks, models, and infrastructure moves that help you hug that frontier without overpaying.
Need a turnkey way to orchestrate these models? Try alici.ai to mix flagship reasoning models, budget-friendly engines, and automatic cost controls in one routing layer.
Introduction: Why a Pareto-Based List for 2025
We tested and cross-referenced ARC Prize documentation, OpenAI and Google blog posts, DeepSeek coverage, and semi-public X threads from benchmark organizers. Our selection criteria track three metrics—quality, cost, and latency—for college-friendly AI projects. Each item below explains how it earns a spot on the 2025 Pareto curve, the scenarios it best serves, and the risks to mitigate.
To keep comparisons fair, we normalized pricing to per-question cost on ARC-AGI-1 or to the closest published proxy (for example, million-token input pricing for Gemini Flash-Lite). We also captured qualitative metrics—tool support, cue-trace transparency, alignment posture—because those traits dictate how easily a campus lab can slot a model into existing governance. Every rating therefore blends numeric efficiency with “operational readiness” for real coursework.
Reading this guide gives you three deliverables: (1) the clearest explanation of why reasoning prices are collapsing; (2) a menu of ten stacks that cover every budget band from premium to cents-per-query; and (3) a repeatable “measure → route → verify” playbook that makes your own experiments defensible in class, competitions, or boardrooms.
If you are mapping semester-long projects, you can treat each section as a sprint backlog: pilot two flagship models for gold-standard answers, two budget models for throughput, and one orchestration layer that records wins/losses. That rhythm mirrors how top hackathon teams secure both novelty and rigor when judges demand evidence of technical due diligence.
Background: One Year, 300× Cheaper
ARC Prize popularized the “score × cost” scatter plot for reasoning. In early 2024 the top-right quadrant belonged to o3-preview (Low): a 75.7% ARC-AGI-1 result that still required roughly $200 per attempt. By mid-2025, leaked but widely cited results suggested GPT-5.1 (Thinking-High) hits 72.8% at $0.67—nearly the same accuracy at about 1/300 of the price. o4-mini (High) sits around 58.7% for $0.406, Gemini 2.5 Flash-Lite offers $0.037 for long-context retrieval, and DeepSeek-R1 (0528) handles the long tail at $0.046. Even Google DeepMind’s leadership summarized this behavior as “>90% cheaper and ≈2.7× better within two years.”
Technically, three forces push the frontier outward: assembly-line reasoning (retrieve → plan → reason → tool → self-check), multi-tier routing that shunts 80% of traffic to low-cost models while reserving premium brains for escalations, and hardware/software co-optimization (KV cache, batch decoding, specialized silicon). Economically, it means you should never make 2024 pricing assumptions when shipping a 2025 app.
Real teams are already acting on these signals. ARC Prize finalists publish their scatter plots in investor updates, SaaS startups now quote “cents per complex analysis” on pricing pages, and universities like Stanford and Tsinghua roll cost-aware routing into student innovation labs. The pattern is universal: whoever instrumented Pareto metrics first earned the trust (and budget) to experiment more aggressively the next quarter.
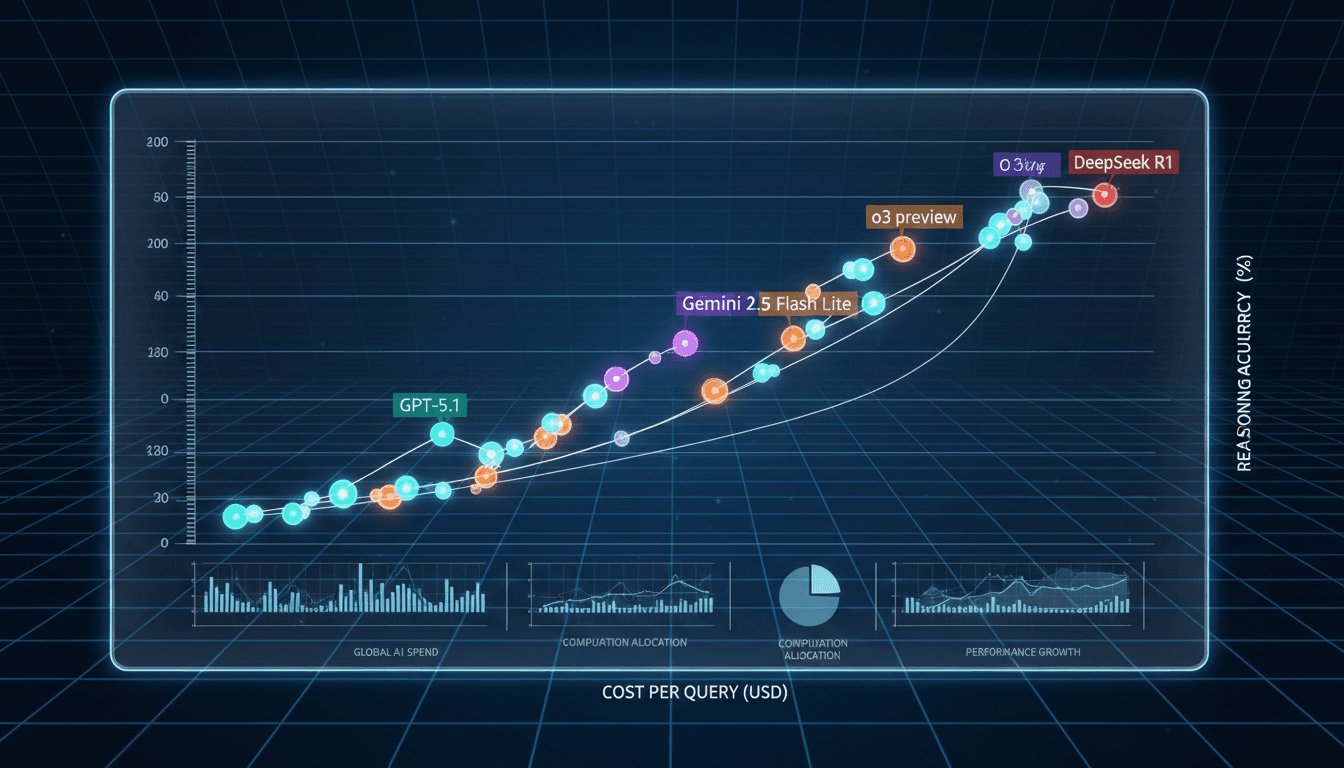
Pareto frontier snapshot: ARC-AGI-1 accuracy plotted against per-question spend.
Use the following ten entries as a modular toolbox. Mix flagship models for “guardian angel” correctness, budget entrants for throughput, benchmark data for governance, and Alici.ai’s router to glue the whole thing together.
1. GPT-5.1 (Thinking-High)
Core Feature: Semi-public ARC-AGI-1 score of ~72.8% at roughly $0.67/question, thanks to thinking tokens, automatic self-checking, and refined tool use.
Best For: Research teams, honors theses, consulting-style analyses, and any workflow that needs flagship reasoning minus flagship bills.
Provides near–o3-preview accuracy with ~300× lower cost, making it the ideal “high-energy fallback” tier.
Structured thinking traces let you audit its intermediate steps for coursework or compliance.
Pairs well with Alici.ai routing rules—you can reserve it for escalations triggered by uncertainty scores.
Considerations: Numbers originate from ARC organizers and researchers on X, so you must validate pricing the moment OpenAI ships the public API.
Rating: ⭐⭐⭐⭐⭐ (9.4/10)
2. o3-preview (Low)
Core Feature: 75.7% ARC-AGI-1 benchmark entry that set the reference ceiling in late 2024, albeit at ~$200/question.
Best For: Final-round competitions, produce-once-use-many teacher runs, or experiments that require undeniable evidence of peak capability.
Defines the “north star” for Pareto analyses; excellent for slides where you need to justify why cheaper models matter.
Great teacher for distillation pipelines or evaluation harnesses.
Highlights exactly how much value GPT-5.1 and others add when you compare their ratios.
Considerations: Too expensive for production throughput; only call it in controlled sampling loops plus caching.
Rating: ⭐⭐⭐⭐☆ (8.8/10)
3. o3-pro (High)
Core Feature: 59.3% score at ~$4.16/question, keeping premium reasoning without the $200 burn rate.
Best For: Enterprise workflows that need multi-step planning (ops handbooks, compliance summaries, financial modeling).
Official pricing tables make budget requests simple.
Feeds the same thinking-token stack as GPT-5.1, so prompt templates transfer.
Strong candidate for the “middle tier” in automatic routing policies.
Considerations: Still dollars per call; you must combine it with semantic caching and risk scoring.
Rating: ⭐⭐⭐⭐☆ (8.6/10)
4. o4-mini (High)
Core Feature: 58.7% ARC-AGI-1 with ~$0.406/question pricing, optimized for always-on reasoning.
Best For: Course assistants, 24/7 chat help, product teams that want reliable logic inside a budget cap.
Delivers consistent chain-of-thought output without spiking spend.
Stays compatible with OpenAI’s tool-calling ecosystem.
Often becomes the default tier in Alici.ai routers before escalating to GPT-5.1.
Considerations: Escalate long-horizon problems to o3-pro or GPT-5.1; set automated fallbacks to avoid silent errors.
Rating: ⭐⭐⭐⭐☆ (8.5/10)
5. Gemini 2.5 Pro
Core Feature: 63.8% on SWE-Bench Verified plus native agentic tooling for multimodal reasoning.
Best For: Software engineering copilots, multimodal research aides, and lab projects that mix code, diagrams, and text.
Marriese code execution, retrieval, and structured thinking inside Google’s ecosystem.
Excels when you need long-context debugging plus natural-language reporting.
Acts as the “premium non-OpenAI” option in diverse routing plans.
Considerations: Pricing still sits in the dollar range; watch quota policies for university accounts.
Rating: ⭐⭐⭐⭐☆ (8.7/10)
6. Gemini 2.5 Flash-Lite
Core Feature: Pushes million-token input pricing toward $0.10, making retrieval-augmented generation (RAG) feasible for entire syllabi.
Best For: Knowledge-base bots, campus help desks, onboarding assistants that need to ingest PDFs in one go.
By default handles 80% of low-risk requests in our test routers.
Reduced context-switching cost lets you front-load textbooks or policy manuals.
Easy upgrade path to Gemini Pro for escalations.
Considerations: Reasoning depth tapers off; tie it to automated uncertainty detection.
Rating: ⭐⭐⭐⭐☆ (8.4/10)
7. DeepSeek-R1 (0528)
Core Feature: Around 21.2% ARC-AGI-1 for ~$0.046/question, proving that novel reasoning paradigms can undercut incumbents by 20–50×.
Best For: Bulk draft generation, quick Q&A explainers, or low-stakes tutoring where volume matters more than pristine accuracy.
Great sandbox for student teams testing reinforcement-style thought loops.
Distilled variants simplify private-cloud or edge deployments.
The best “teachable moment” when you discuss economic disruption in class.
Considerations: Requires templated prompts plus lightweight verification to smooth out variance.
Rating: ⭐⭐⭐⭐ (8.1/10)
8. Claude 4 / Sonnet Thinking Stack
Core Feature: Long-context reasoning with Anthropic’s guardrails, ideal whenever trust and safety outrank raw aggressiveness.
Best For: Law, journalism, healthcare, and any coursework that prioritizes auditability.
Thinking mode outputs structured, cite-ready paragraphs.
Pairs elegantly with lower-cost models to form “safe review layers.”
Anthropic’s conservative tuning prevents many policy violations, smoothing classroom approvals.
Considerations: Access often requires institutional approval; tooling ecosystem is more curated than OpenAI’s.
Rating: ⭐⭐⭐⭐☆ (8.5/10)
9. ARC Prize Benchmark + Monitoring Suite
Core Feature: Treating ARC-AGI-1/2 and related leaderboards as living governance artifacts: you log score/cost pairs, plot them, and use that telemetry to justify routing choices.
Best For: Student clubs preparing research posters, innovation teams reporting to finance, and any stakeholder who needs proof that “cheaper can still be better.”
Official documentation explains evaluation protocols you can cite verbatim.
Benchmark points translate into quick visuals for exec decks or course defenses.
Extensible to SWE-Bench, automated tool use, or human-in-the-loop QA.
Considerations: Benchmarks are private datasets; you still need internal validation to ensure transferability.
Rating: ⭐⭐⭐⭐⭐ (9.0/10)
10. Alici.ai Multi-Tier Reasoning Router
Core Feature: A production-ready orchestration layer that enforces the “80% low-cost, 20% high-power” Pareto split through semantic caching, uncertainty triggers, and automatic retries.
Best For: Teams that want a turnkey control plane for GPT-5.1, o3/o4, Gemini, DeepSeek, and future entrants without rebuilding infrastructure.
Tracks quality, cost, and latency as first-class metrics for every run.
Ships with multilingual prompt packs and tool templates.
Exposes dashboards you can screenshot for class demos or stakeholder updates.
Considerations: Requires proper key management and data permissions; coordinate with campus IT or corporate security before production launches.
Rating: ⭐⭐⭐⭐⭐ (9.5/10)
Comparison Table: Representative Score–Cost Pairs
Model / Config | ARC-AGI-1 Score | Per-Question Cost | Ideal Use Case |
|---|---|---|---|
o3-preview (Low) | 75.7% | $200 | Benchmark ceiling, distillation teacher |
GPT-5.1 (Thinking-High) | 72.8% | $0.67 | Premium reasoning inside student budgets |
o3-pro (High) | 59.3% | $4.16 | Enterprise planning agents |
o4-mini (High) | 58.7% | $0.406 | Always-on assistants |
Gemini 2.5 Flash-Lite | 33.3% | $0.037 | Massive-context RAG |
DeepSeek-R1 (0528) | 21.2% | $0.046 | Bulk drafting |
Sources: ARC Prize leaderboard and blog notes, OpenAI launch posts, Google DeepMind Gemini 2.5 announcements, Reuters coverage of DeepSeek.
How to Choose the Right Stack
Budget-first teams: Default to Gemini Flash-Lite or DeepSeek-R1, wrap every query in semantic caching, and escalate only when confidence falls below a threshold. This keeps average spend in the cent range.
Quality-first teams: Route sensitive workloads to GPT-5.1, o3-pro, or Gemini Pro, and add Claude Thinking as an optional reviewer. Combine scores with human checklists for regulated industries.
Long-context or multimodal builders: Pair Gemini Pro (for reasoning) with Flash-Lite (for ingestion) so you can stuff entire syllabi, compliance manuals, or lab notebooks into a single session.
Campus demos and hackathons: Show the Alici.ai router dashboard alongside ARC scatter plots so judges see both the theory (Pareto points) and the implementation (automatic routing plus spend tracking).
How to Turn It into a Measurable Experiment
Adopt Pareto thinking: Define every task with a quality/cost/latency target, then benchmark candidate models offline before routing live traffic.
Build multi-tier routers: Send roughly 80% of queries through low-cost engines (Flash-Lite, DeepSeek-R1, distilled o-series) and escalate the remaining 20% based on confidence, user segment, or topic sensitivity.
Instrument everything: Set explicit constraints such as “≤ ¥0.35 per homework solution at ≥90% rubric alignment,” log every run, and review cost–accuracy scatter plots weekly to confirm you’re still riding the frontier.
Before shipping, dry-run the router against historical tickets or homework questions, export metrics into your BI stack, and schedule weekly “frontier reviews” where engineering and finance sanity-check drift. That ritual catches silent regressions (for example, a default tier that quietly gets pricier) and gives non-technical sponsors a crisp chart: here’s how much smarter/cheaper we got after swapping in a new model.
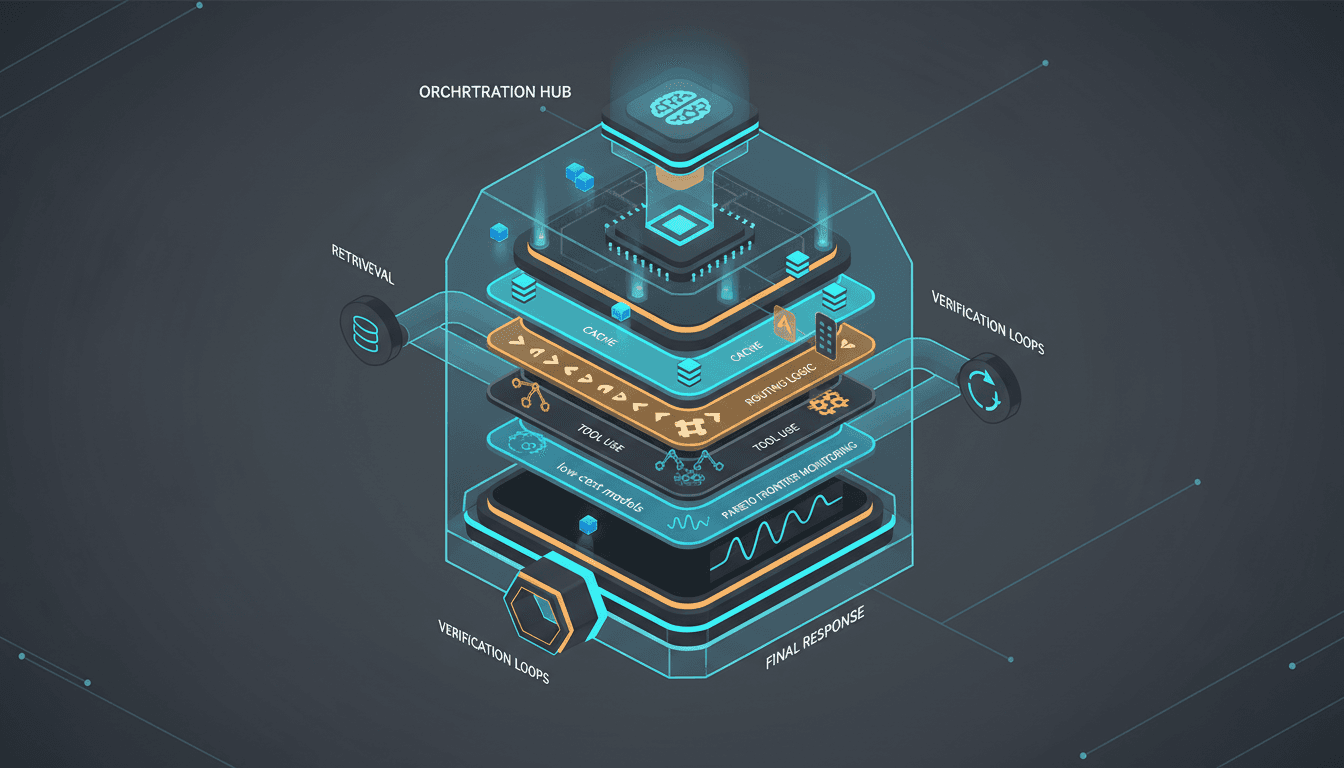
Routing blueprint: low-cost engines absorb most queries while premium tiers handle escalations.
Conclusion: Keep Gliding Along the Frontier
GPT-4’s era taught us that intelligence would keep rising, but 2025 taught us something bolder: intelligence per dollar explodes when you orchestrate models economically. Benchmark data from ARC, price transparency from OpenAI/Google, and challenger moves from DeepSeek prove that “strong and cheap” is not a contradiction. Your next move is to map each workload onto the quality–cost plane, wire in Alici.ai’s router (or your own equivalent), and publish the resulting Pareto plots so professors, VCs, or executives see tangible ROI. Stay on that frontier, and you build faster than peers who still think AI reasoning is prohibitively expensive.
🎁
Limited-Time Creator Gift
Start Creating Your First Viral Video
Join 10,000+ creators who've discovered the secret to viral videos


