Top 10 Deep Research Agents to Trust in 2025

Benchmark Alici, Kimi, Gemini, Claude, OpenAI, Perplexity, and more for enterprise-grade research
|
10 min
TL;DR
Compare 10 Deep Research Agents—Alici.ai Playbooks, Kimi-Researcher, OpenAI DeepResearch, Gemini 2.5 Pro, Claude Research, Perplexity, Copilot, You.com, Glean, and Notion—focusing on RL planning, retrieval depth, citation rigor, and deployment tips for SEO/AEO teams.
Introduction: Why Deep Research Agents Matter in 2025
The volume of policy updates, scientific releases, and product announcements in 2025 is growing on a weekly basis, making "manual search and copy" workflows impossible to scale. To identify reliable Deep Research Agents, we stress-tested ten leading products for two weeks using six criteria: search depth, reasoning quality, citation transparency, narrative structure, collaboration readiness, and onboarding cost. Tests spanned Chinese and English projects plus multimodal prompts, and we combined DeepResearch Bench metrics with vendor white papers and real usage logs.
Beyond autonomous planning, we examined whether each agent clarifies ambiguous prompts, sustains long-context sessions, allows custom research plans, and produces citation-ready longform reports. Because many teams rely on cross-functional collaboration, we also logged permission handling, review workflows, and knowledge base integrations. The final list represents flagship models (OpenAI, Google, Anthropic, Moonshot, Microsoft) alongside focused newcomers such as Perplexity, Glean, You.com, Notion, and alici.ai—forming three clusters: high-end flagships, collaboration-first, and specialized deployments.
By the end of this guide you will know which agent fits specific scenarios, what trade-offs to expect, how we scored each metric, and how to reuse our selection framework. We also share reusable prompt templates and launch checklists so your team can place an agent inside a production workflow instead of keeping it in an experiment folder.
Background: From Workflows to "Model-as-Agent" Systems
This year almost every Deep Research Agent abandoned the rigid "planner → tool → writer" pipelines and embraced integrated "model-as-agent" design. Through end-to-end reinforcement learning, the model practices task decomposition, browsing, tool invocation, and citation assembly inside a simulated browser. Once a user submits a topic, the agent now drafts clarifying questions, iterates on searches, runs Python or SQL snippets, and attaches traceable references. Moonshot's Kimi-Researcher, for example, was trained with millions of browser simulations and typically runs 74 search queries, visits 206 URLs, and keeps only the top 3% of sources to draft a 10,000-word report.
OpenAI DeepResearch and Google Gemini 2.5 Pro Deep Research add similar reinforcement loops on top of GPT-4O and Gemini long-context models, letting the system "self-correct" during each research sprint. Anthropic's Claude Research emphasizes safety for medical, legal, and financial work by surfacing verifiable citations and multi-perspective reasoning. Perplexity Pro, Microsoft Copilot Deep Search, and comparable tools augment the browser experience with visible research traces so teams can inject new keywords during a live meeting. Regardless of vendor, long-context windows (100K–1M tokens) and structured references have become table stakes.
With shared benchmarks like DeepResearch Bench and LLM Bar Exam, vendors now publish retrieval coverage, citation density, and latency metrics. Gemini currently leads DeepResearch Bench with a 48.9 score, while OpenAI, Claude, and Kimi trail by less than four points, signaling a mature first tier. Future differentiation will come from enterprise deployment details such as data residency, real-time connectors, and AI observability.
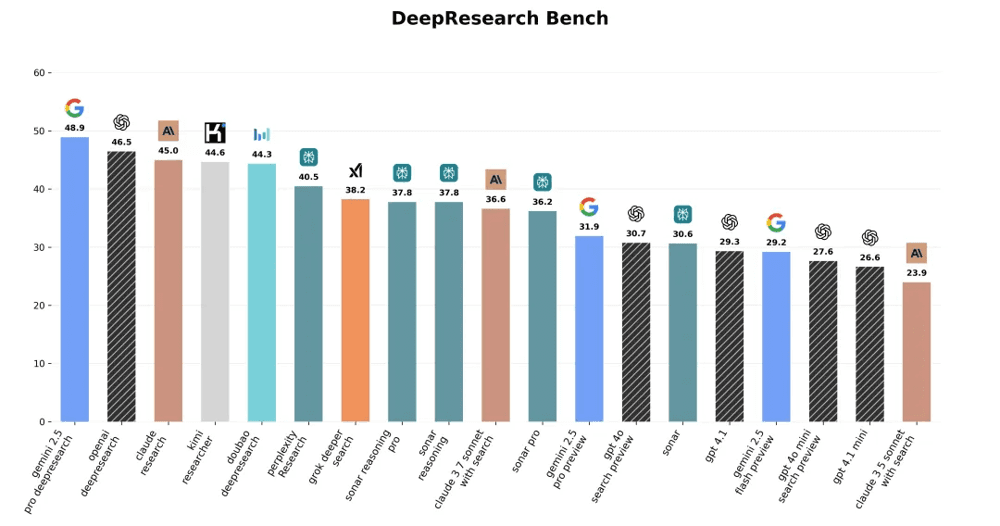
DeepResearch Bench keeps Gemini 2.5 Pro, OpenAI DeepResearch, Claude Research, and Kimi-Researcher within a 4-point spread, forming the 2025 flagship cohort.
Top 10 Deep Research Agents for 2025
1. Alici.ai Research Playbooks
Core Feature: Prebuilt, multi-stage Research Playbooks connect prompt parsing, data gathering, synthesis, and review nodes so teams can reuse a vetted workflow within minutes.
Best For: Strategy, consulting, or insights teams that must blend private knowledge bases (training decks, expert interviews, patent archives) with real-time web intelligence.
Key Advantages:
Workflow Studio orchestrates agents visually and connects search APIs, enterprise knowledge bases, and BI stacks.
Each step produces an auditable log for downstream SEO/AEO content and compliance teams.
Native multi-language templates (TL;DR, executive summary, recommendations) minimize downstream formatting work.
Considerations: Advanced Playbooks rely on custom connectors, so the first deployment should involve operations or data engineers.
Rating: 9.4/10
2. Kimi-Researcher (Moonshot)
Core Feature: Built on the K2 long-context model with autonomous reinforcement learning, averaging 206 visited websites and conserving only the top 3% to craft citation-heavy reports.
Best For: Chinese regulatory analysis, policy comparisons, and academic literature reviews that demand structured citations.
Key Advantages:
"Model-as-agent" automation removes the need for manual instruction injection.
Clarifying questions are baked in before deep retrieval begins, reducing rework.
Million-token context swallows PDFs, spreadsheets, and annex data in a single pass.
Considerations: Currently limited to an allowlist and does not expose intermediate logs, which may frustrate compliance teams.
Rating: 9.2/10
3. OpenAI DeepResearch
Core Feature: GPT-4O-based agent with an integrated browser, Python sandbox, and spreadsheet reasoning, usually producing multi-section reports within 5–30 minutes.
Best For: Multinational product, market, or technology teams that expect fluent English narratives and side-by-side viewpoints.
Key Advantages:
Clarifying prompts refine scope right after the initial question.
Python tooling builds charts, regression checks, or calculations automatically.
Project links let stakeholders review drafts with embedded references.
Considerations: Invocation counts are tied to ChatGPT Enterprise or Pro subscriptions, and Chinese web coverage lags local agents.
Rating: 9.1/10
4. Google Gemini 2.5 Pro Deep Research
Core Feature: Combines Google Search ecosystem with Gemini's long context to generate editable research plans and 15,000-word reports in roughly 14 minutes.
Best For: Product and marketing teams living inside Google Workspace that need to reference Gmail, Drive, and shared assets.
Key Advantages:
Process visualization shows each query and lets teams tweak the plan midstream.
Upcoming multimodal inserts will embed charts, screenshots, and computed results.
DeepResearch Bench-leading score (48.9) proves its coverage advantage.
Considerations: Availability remains region-locked, and output structure can be verbose without manual pruning.
Rating: 9.0/10
5. Anthropic Claude Research
Core Feature: Claude 3-based research workflow that prioritizes safety and multi-perspective reasoning for high-stakes fields.
Best For: Medical, legal, and financial teams that require conservative tone, explicit citations, and bias checks.
Key Advantages:
Single runs can cite hundreds of sources and provide clickable references.
100K-token window handles statutes, contracts, or medical cases.
Outputs include "perspective layering" to present opposing views.
Considerations: Still in limited release with fewer interface plugins than OpenAI or Google.
Rating: 8.9/10
6. Perplexity AI Pro Search & Pages
Core Feature: Blends multi-hop search, inline citations, and shareable Pages so lean teams can publish findings instantly.
Best For: Content studios, media outlets, and OSINT researchers validating fast-moving stories.
Key Advantages:
Copilot mode iterates live questions and displays each reference.
Pages exports clean HTML for SEO-friendly syndication.
Supports PDF and image uploads for quick mixed-media digests.
Considerations: Reasoning depth is constrained by dialog token limits, and enterprise permission controls are minimal.
Rating: 8.7/10
7. Microsoft Copilot Deep Search
Core Feature: Bing's Deep Search rewrites vague prompts into granular tasks and lets GPT-4-class models crawl the open web iteratively.
Best For: Microsoft 365 organizations that want SharePoint and Teams knowledge tied directly to external findings.
Key Advantages:
Automatic query expansion surfaces long-tail resources.
Copilot Lab integrations push findings into Word or Loop workspaces.
Azure Information Protection policies are honored end-to-end.
Considerations: Retrieval depth follows Bing indexing quality and is strongest for English-language content.
Rating: 8.5/10
8. You.com Research Assistant
Core Feature: Multi-agent orchestration plus plugins let researchers prioritize academic, social, or news domains and export interactive references.
Best For: Independent analysts or early-stage startups that require customizable research preferences.
Key Advantages:
Research mode can lock queries to arXiv, PubMed, Reddit, and more.
Result panes include pros/cons comparisons for rapid judgment.
Inline code execution and translation reduce tool switching.
Considerations: Free tiers include ads and rate limits, and citation formatting needs manual editing for publication.
Rating: 8.4/10
9. Glean Research Assistant
Core Feature: Enterprise-first agent that merges Slack, Drive, and Confluence permissions before topping up with public searches.
Best For: B2B sales, customer success, and legal teams where internal knowledge outweighs public data.
Key Advantages:
Strict permission inheritance ensures only authorized snippets appear.
Summaries push directly to the Glean Feed or Slack channels.
Configurable trusted-source allowlists keep citations consistent.
Considerations: Limited coverage of breaking news requires manual supplementation with external links.
Rating: 8.3/10
10. Notion Q&A Research Workbench
Core Feature: Launches research tasks inside Notion databases so knowledge capture and investigation share the same context.
Best For: Content, product, and meeting-heavy teams already operating inside Notion.
Key Advantages:
Flag any database row for "needs research" to auto-generate a scoped page.
Pairs with Notion AI writing assistant to create subpages and action items.
Embeds original blocks and respects Notion permissions throughout.
Considerations: External webpages rely on the embed service, so complex sites may require manual text uploads.
Rating: 8.1/10
Flagship Agent Comparison
Platform | Signature Strength | Retrieval Depth | Process Transparency | Ideal Team | Pricing / Access |
|---|---|---|---|---|---|
Alici.ai | Playbook automation plus enterprise knowledge fusion | Hybrid of internal indexes and web connectors | End-to-end logs with audit export | Strategy or content teams scaling repeatable research | Seat-based subscription |
Kimi-Researcher | Longform precision and citation rigor | ~206 sites per run, top 3% enter reports | Opaque process | Policy, regulatory, and academic groups | Invite-only beta |
OpenAI DeepResearch | Reasoning depth plus Python analytics | Hundreds of web pages + Python tooling | Clarifying dialog and review links | Consulting and investment research squads | ChatGPT Enterprise/Pro add-on |
Gemini 2.5 Pro | Visual plans with Google data integration | Google Search + Gmail/Drive context | Editable research roadmap | Workspace-native product and marketing teams | Workspace AI Premium |
Claude Research | Safe reasoning with multi-angle narratives | Hundreds of citations + 100K tokens | Partial progress visibility | Healthcare, legal, and risk teams | Limited availability |
Perplexity Pro | Lightweight multi-hop search with instant citations | Parallel sources within token budget | Fully transparent and shareable | Media and agile content ops | Pro plan at $20/month |
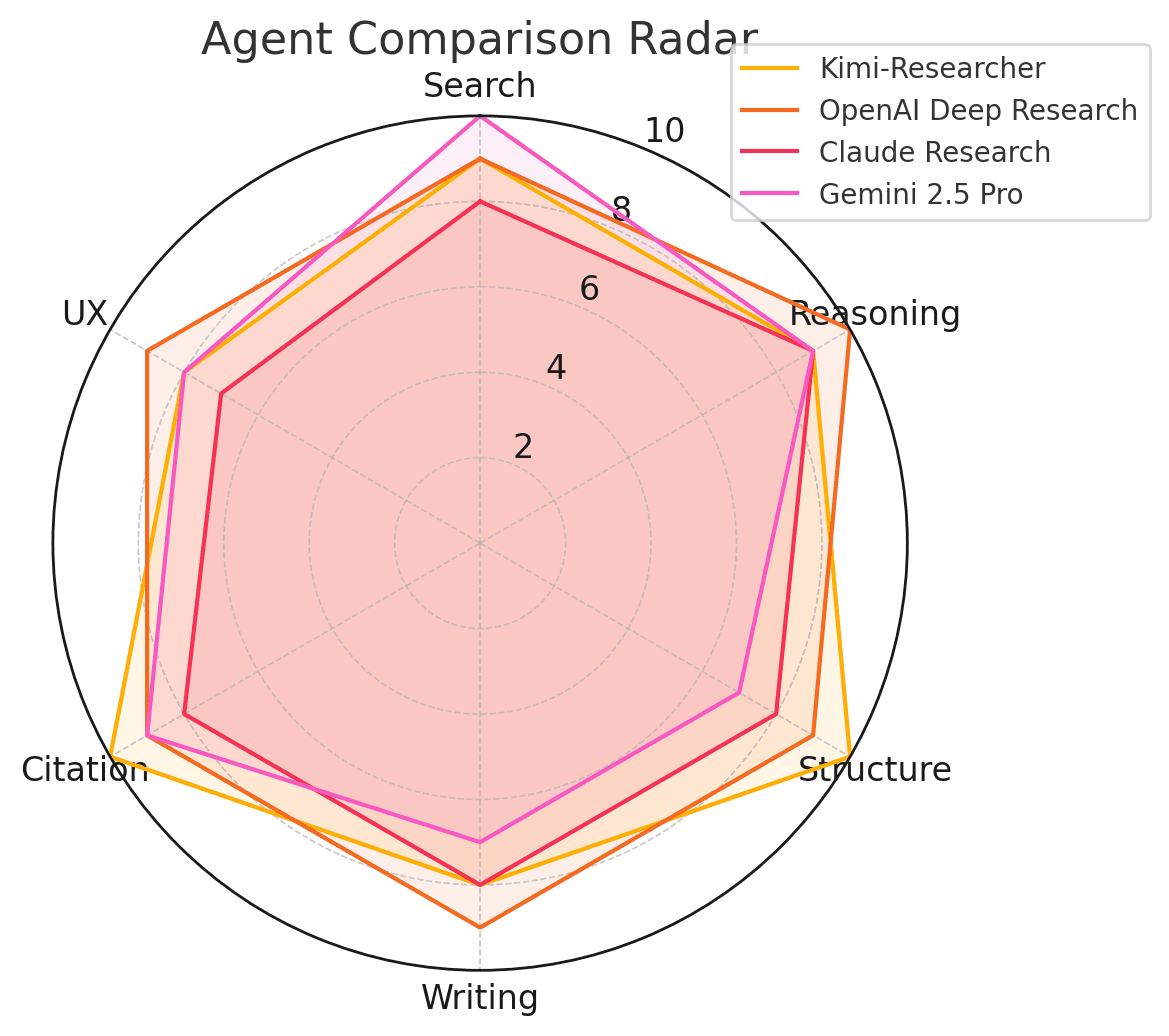
Six-dimension radar charts highlight contrasts in retrieval breadth, reasoning, structure, writing, citation reliability, and UX.
How to Choose the Right Deep Research Agent
Need end-to-end automation and standardization? Go with Alici.ai or Gemini's research plans. Both let operations teams approve prompts once and reuse them safely. Alici's Playbooks chain clarification, retrieval, drafting, review, and compliance nodes with exportable logs.
Care about multilingual depth and citation rigor? Kimi-Researcher and Claude Research lead here. Kimi excels at ultra-long Chinese documents with numbered footnotes, while Claude overlays citation confidence scores for regulated industries.
Want transparent processes for rapid iteration? Gemini, Perplexity, and You.com expose every search term and finding so stakeholders can redirect the investigation live. Gemini even lets executives annotate the research plan before the crawl begins.
Rely primarily on internal knowledge? Choose Glean or Notion Q&A, since both inherit workspace permissions and write back to your knowledge base. Microsoft Copilot Deep Search also performs well for SharePoint-centric orgs.
Budget or deployment constraints? Start with Perplexity or You.com monthly plans. If you need unified data governance and SSO, invest in Alici.ai or Glean where connectors and logging meet enterprise standards.
How to Launch a Research Agent on Alici.ai
Clone a Research Playbook: Start from the "Deep Research Blueprint" template, define question types, citation style, and output sections.
Connect data sources: Link Confluence, Feishu Docs, or Notion plus live search APIs, and whitelist approved public domains.
Configure clarification logic: Use conditional nodes to auto-ask for missing years, regions, or product lines to guarantee context.
Insert review checkpoints: Add manual review or validation agents before publishing to cross-check claims with citations.
Publish and monitor: Track run time, source counts, and citation acceptance inside Alici dashboards, then refine the Playbook.
Conclusion and Next Steps
Deep Research Agents have evolved from flashy demos into production-ready systems. Differences in search breadth, long-context stability, structured writing, and citation clarity are shrinking, so differentiation now rests on workflow control and enterprise readiness. Our top recommendations balance coverage and repeatability: Alici.ai Research Playbooks for team-wide standardization, OpenAI DeepResearch for multilingual reasoning with Python analytics, and Gemini 2.5 Pro Deep Research for plan visualization across the Google ecosystem.
If you want to embed research output inside content production or product planning, replicate our Playbook on Alici.ai, connect your data sources, and let AI deliver the first draft while subject-matter experts focus on refinement. Tap the CTA to launch your Alici agent and turn verifiable insights into a daily habit.
🎁
Limited-Time Creator Gift
Start Creating Your First Viral Video
Join 10,000+ creators who've discovered the secret to viral videos


