0:00 / 0:00



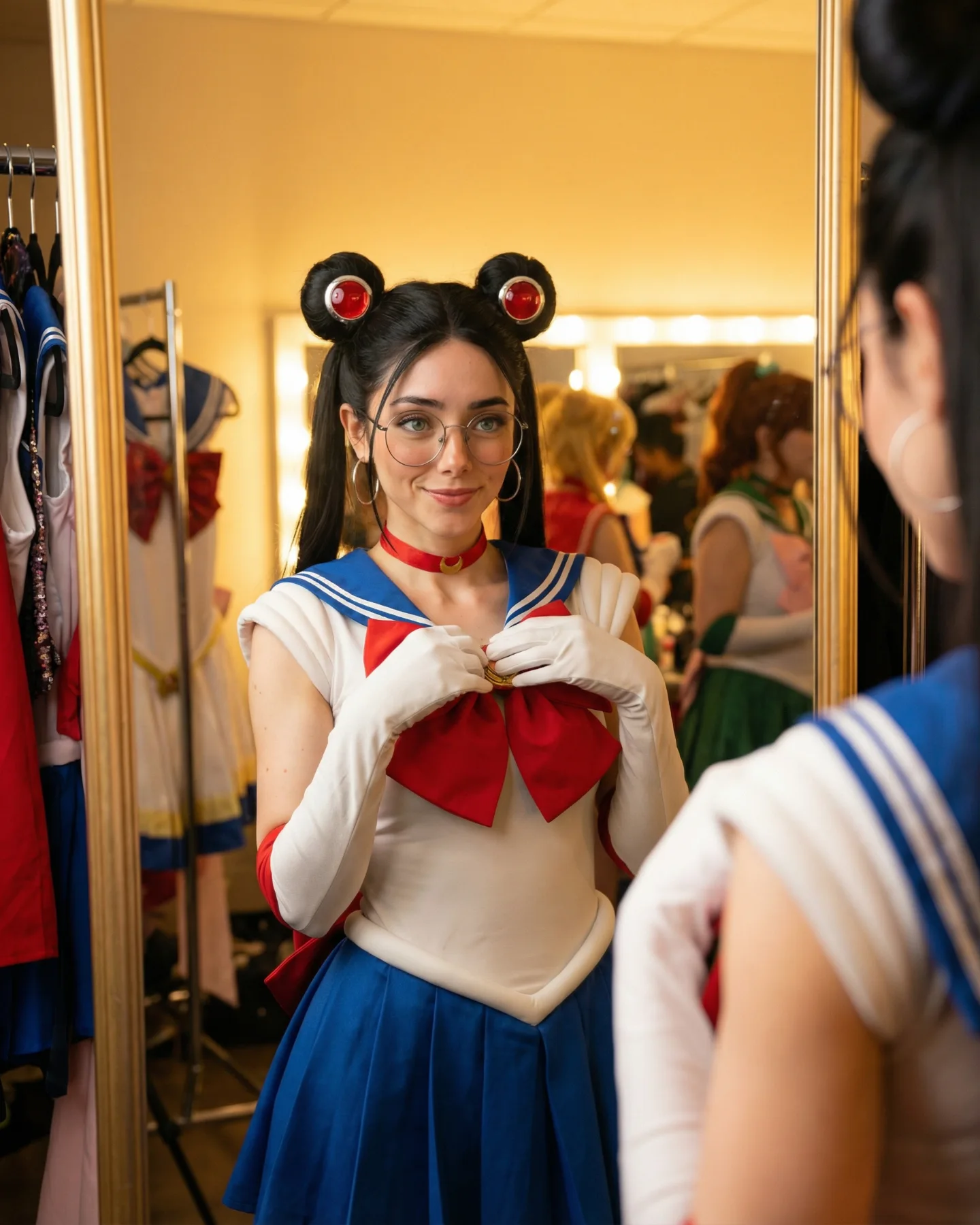












Sailor Moon 🌙💕 Como muchos me habéis pedido un Cosplay de Sailor Moon, aquí tenéis una pequeña secuencia 🙊 Si quieres los prompts comenta "ARIA" y te lo paso por mensajes 💌
Sailor Moon 🌙💕 Como muchos me habéis pedido un Cosplay de Sailor Moon, aquí tenéis una pequeña secuencia 🙊 Si quieres los prompts comenta "ARIA" y te lo paso por mensajes 💌
This short cosplay clip works because it does not try to build a huge fantasy world. Instead, it places the character in a believable dressing-room moment and lets the viewer enjoy the transformation up close. The result is more intimate than a stagey cosplay reveal and more useful for creators who want to reproduce the look with AI video tools. The clip sells identity, styling, and atmosphere through a few highly readable signals: the Sailor Moon wardrobe, the recognizable odango buns with long twin tails, the mirror bulbs, the makeup desk, and the relaxed hand-to-hair gestures.
The subject appears in a vertical vanity setup, dressed in a Sailor Moon inspired outfit with a red bow, blue sailor collar, blue pleated skirt, white gloves, and a red choker. She wears glasses, which adds a softer, slightly modernized variation to the cosplay. The scene unfolds as a tiny dressing-room beauty moment. She smiles, checks herself in the mirror, touches her hair, and subtly adjusts her face framing. There is no large movement, no location change, and no narrative twist. The entire clip is built around a polished, charming pose progression.
That simplicity is important. For AI video prompting, minimal but specific actions usually reproduce more reliably than overdescribed plot-heavy actions. “She gently adjusts her hair at a lit vanity mirror” is repeatable. “She transforms into a magical warrior while acting out multiple emotional beats in a moving camera sequence” is much less stable. This clip is strong because the action is narrow but visually rich.
There are five major anchors that make the clip instantly legible. First is the hairstyle. Sailor Moon is signaled immediately by the double buns and long tails. Second is the wardrobe palette: white, blue, and red, arranged exactly where viewers expect them. Third is the vanity mirror with round bulb lights, which creates a backstage or getting-ready context instead of a generic bedroom. Fourth is the hand choreography, because hair-touching and cheek-touching naturally support a beauty or cosplay presentation. Fifth is the expression: soft smile, slightly shy confidence, and a sense that the subject is admiring the finished look.
When reproducing this clip, the prompt should keep those anchors fixed before adding secondary details. If the hairstyle, costume blocks, and vanity lighting are correct, the clip will read correctly even if minor cosmetics or tabletop objects vary. If those anchors drift, the video quickly stops feeling like a Sailor Moon vanity moment and turns into generic cosplay content.
The location appears to be an indoor vanity corner or dressing area, not a full theatrical set. The mirror bulbs do most of the storytelling work. They imply performance preparation, beauty routine, and intimacy all at once. The makeup tools on the tabletop support the illusion that this character is being assembled in real time. For AI generation, this environment matters because it creates a coherent reason for the close-range hand gestures. The subject is not touching her hair randomly; she is checking a look in the mirror.
That logic should be preserved in the generated result. Background clutter should stay intentional and beauty-related: brushes, small bottles, makeup containers, a tabletop mirror frame, and warm practical lighting. Avoid replacing the setup with a bedroom wall, neon cyberpunk lights, or a fantasy moon backdrop if the goal is to match this reference. The power of the original clip comes from the contrast between iconic anime costume design and a believable real-life prep space.
The camera language is restrained. This is not an action sequence and not a high-concept commercial move. The shot behaves like a stable phone or lightly stabilized vertical social clip. Framing stays medium and readable, prioritizing the upper body, hair silhouette, and costume chest details. Because the movement is subtle, the viewer has enough time to inspect the styling. That pacing is critical for cosplay videos, beauty content, and fashion reveals. If the camera moves too aggressively, the costume design gets lost.
A good recreation prompt should therefore ask for a mostly locked medium shot at eye level, with only tiny body-driven motion and slight organic camera drift. The goal is not cinematic spectacle. The goal is confidence, warmth, and visual clarity. This kind of prompt tends to perform better in current image-to-video and text-to-video models because it reduces the number of moving variables.
The lighting is dominated by warm vanity bulbs, which creates a flattering beauty look. The face is evenly readable, the glasses catch highlights, and the blonde hair gains shine without becoming overexposed. The warm light also makes the red bow and blue collar feel richer because the surrounding environment stays in warm neutral tones. This is a classic trick in beauty and dressing-room imagery: use warm practicals to create a comfortable glow, then let saturated wardrobe colors stand out against that warm field.
In prompt terms, this means you should specify warm tungsten bulb lighting, frontal and slightly surrounding the face, with soft shadows and practical reflections in the glasses and hair. The grade should stay clean and polished, not gritty, not desaturated, and not aggressively cinematic. This is social content with editorial polish, not a dark drama scene.
The motion vocabulary is intentionally small. The subject smiles, checks her hair, touches her cheek, and shifts posture slightly. These micro-actions are enough because the costume and environment already provide strong visual interest. Overanimating the body would actually weaken the piece by turning it into performance instead of presentation. The charm comes from the in-between moment, as if the viewer caught the character just after finishing makeup and before stepping out.
When writing prompts for clips like this, it helps to think in terms of “beauty motions” rather than “story motions.” Beauty motions include brushing hair back, adjusting a shoulder line, lifting the chin, smiling into the mirror, or letting the hair sway lightly as the body settles. Story motions include running, spinning, dramatic turning, or interacting with multiple props. The first category matches this video. The second would pull the generation away from the reference.
Start by locking the non-negotiables: one young woman, Sailor Moon inspired costume, odango buns with long blonde twin tails, white gloves, glasses, warm bulb-lit vanity mirror, cosmetics visible on the table, vertical frame, and a soft smile. Then define the motion narrowly: she adjusts her hair and cheek while admiring herself in the mirror. Keep the shot length short, around five seconds, and avoid scene cuts or angle changes if the goal is a close match.
If your model allows camera instructions, ask for a medium eye-level framing with a 35mm to 50mm equivalent feel, slight handheld breathing, and no dramatic dolly move. If your model allows styling cues, ask for clean editorial beauty lighting, realistic skin texture, glossy highlights in the hair, and saturated but natural costume colors. If your model supports negative prompting, suppress chaotic hand motion, costume deformation, extra accessories, floating hair artifacts, and mirror/background inconsistencies.
For this reference, priority order matters:
1. Character silhouette and hairstyle.
2. Costume color blocking and accessories.
3. Vanity mirror environment with round bulbs.
4. Soft beauty gestures near hair and face.
5. Warm, flattering lighting and stable vertical framing.
If the AI model starts drifting, correct those items in that order. Many creators try to fix low-level texture issues first, but for this kind of clip the high-level silhouette and set logic matter far more than tiny fabric details.
This example is valuable because it teaches a broader lesson about AI video prompting for cosplay and character-inspired content. Successful short-form clips are often built from a small number of highly legible visual signals repeated consistently across a simple action. That is exactly what happens here. The clip is not trying to do too much. It chooses one recognisable character identity, one believable location, one flattering lighting setup, and one gentle pose progression. That combination is easier to reproduce, easier for viewers to parse, and easier for search engines to understand as a distinct content pattern.
For creators building similar pages or assets, this is also a useful growth case study. If someone wants to attract viewers interested in cosplay prompts, anime-inspired fashion videos, vanity mirror setups, or feminine character transformation aesthetics, a piece like this provides a practical template. It is specific enough to be searchable and broad enough to inspire adjacent concepts.
You can create adjacent versions of this prompt while preserving the original logic. Keep the vanity mirror and beauty routine structure, but change the character inspiration. Or keep the Sailor Moon costume identity, but alter the expression from shy smile to playful confidence. Or keep the same character and mood, but switch from glasses-on to glasses-off. These are safe variations because they do not break the clip's primary logic. Unsafe variations would include changing the room to an outdoor location, introducing fight choreography, or moving into a completely different camera style.
That is the practical takeaway from this reference: stable concept, stable environment, stable light, controlled motion. Those four things are enough to generate a polished short clip that feels intentional and re-creatable.